
مدل برنامه نویسی Map Reduce جهت انجام عملیات پردازشی موازی بر روی خوشهای از کامپیوترها (Computer Cluster) کاربرد دارد. در واقع این مدل برنامه نویسی، خود از دو قسمت Map یا همان نگاشت و Reduce یا همان کاهش تشکیلی شده است.
اجازه بدهید مثال کلاسیک Map Reduce را با هم مرور کنیم. فرض کنید، شما یک مجموعه متن دارید. مثلا ۱۰۰۰متن خبری که هر کدام نوشتههای خود را دارند (مثلا ۱۰۰۰خبر مختلف در حوزه سیاسی). حالا میخواهید از بین کل این متون، تعداد تکرار هر کلمه را پیدا کنید. مثلا کلمه رئیس ممکن است ۱۵۰بار در این مجموعه ۱۰۰۰تایی متن اخبار آمده باشد. میخواهیم این کار را به صورت موازی با مدل Map Reduce انجام دهیم. دادهها را به ۵ قسمت که هر کدام شامل ۲۰۰ متن خبری است تقسیم میکنیم. روش کلی Map Reduce دارای سه فاز میباشد که سعی داریم با توجه به مثال بالا این سه فاز را توضیح دهیم. فاز Map، فاز Grouping و فاز Reduce. در شکل زیر این سه فاز نمایش داده شدهاند. به تصویر زیر دقت کنید:
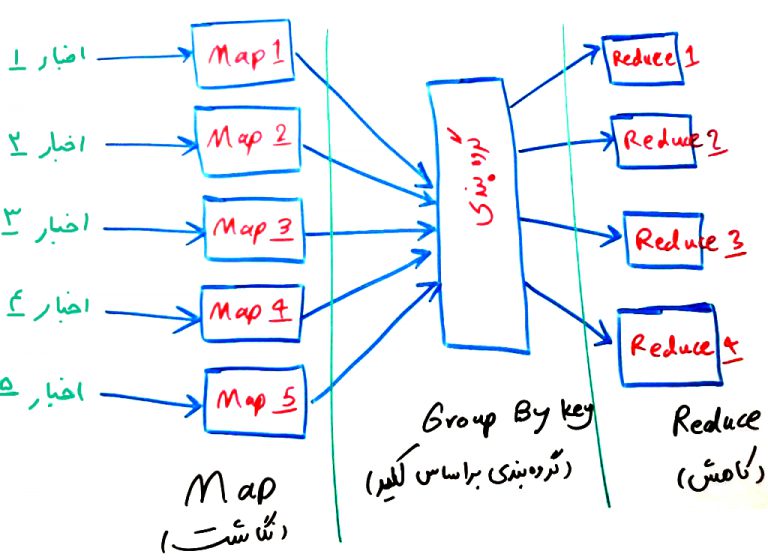
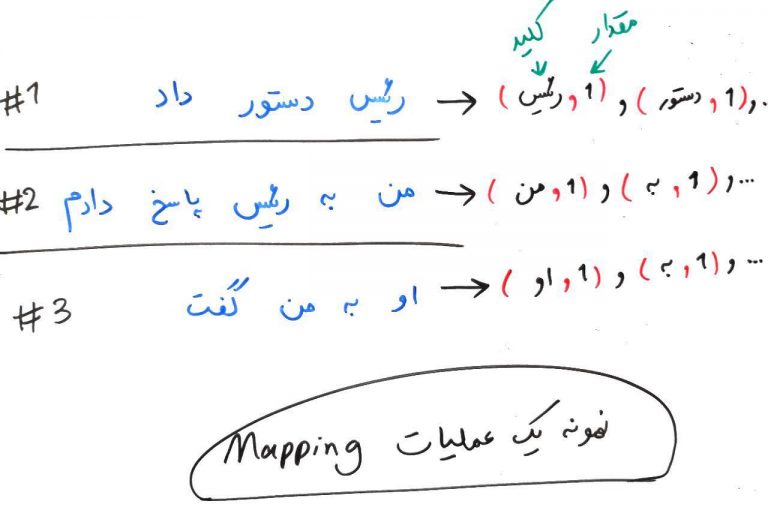
همانطور که مشاهده میشود، ۵ فایل داریم که در هر کدام ۲۰۰خبر قرار دارد. در فاز Map یا همان نگاشت، برای هر کدام از این ۵قسمت، کلمات را به صورت یک زوج کلید/مقدار (Key/Value) اسختراج میکنیم. مثلا فرض کنید زوج (۱/رئیس) را مشاهده میکنید که در قسمت اول ۲بار آمده است. در قسمت دوم و سوم این زوج دیده نمیشود و در قسمت چهارم و پنجم یک مرتبه آمده است.. در واقع ما از هر کدام از متون، کلمات را جدا کردهایم و به صورت یک زوج کلید/مقداری به نمایش درآوردهایم. اگر برایتان تحلیل چگونگی این کار مشکل است، تصویر زیر را نگاه کنید. در این تصویر، یک متن نمونه داریم و بعد از عملیات Map (نگاشت) این متن به کلید/مقدارهای سمت راست تبدیل میشود:
حال دوباره به شکل اول برمیگردیم. الان عملیات Map را انجام دادهایم و به سراغ عملیات گروه بندی (Grouping) میرویم. در عملیات گروه بندی که بر اساس کلیدها انجام میشود، کلیدها (برای مثال رئیس) به ترتیب مرتب میشوند و مقادیر آنها پشت سرهم میآید. با این کار، مقادیر کلیدهایی که مانند هم هستند در کنار یک دیگر قرار میگیرند. مثلا اگر ۱۵۰بار کلمه رئیس تکرار شده باشد، زوج کلید/مقدار بعد از عملیات گروه بندی به صورت ([۱,۱,۱,۱,۱,۱…],رئیس) خواهد بود که تعداد ۱ها ۱۵۰بار تکرار میشود. مانند شکل زیر:

حالا نوبت به فاز آخر میرسد. فاز کاهش یا همان Reduce. در اینجا کلیدهایی که مانند هم هستند به یک کاهنده یا همان Reducer داده میشود. این کاهنده، میتواند عملیات مختلفی را بر روی این گروه از کلیدهای مشابه انجام دهد. برای مثال، ما اینجا جمع تمامی مقادیر مربوط به یک کلید (در واقع یک کلمه از متن اخبار) را محاسبه میکنیم. شکل زیر را نگاه کنید. این شکل عملیات کاهش را برای یک نمونه آماده شده توسط فازهای Map و Grouping نمایش میدهد:
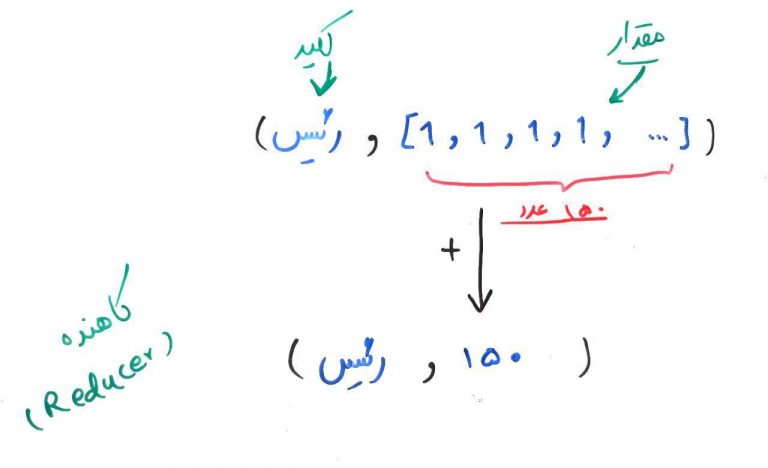
در واقع در اینجا جمع تمامی ۱ها برای هر کدام از کلمات (کلیدها) انجام شده است. مثلا کلمه رئیس در کل متون ۱۵۰بار تکرار شده است. یعنی ۱۵۰ بار عدد ۱ را با هم جمع میکنیم و در نهایت زوج کلید/مقدار به صورت (۱۵۰/رئیس) در خروجی نمایش داده میشود.
نکته اصلی در عملیات Map Reduce این است که فرآیند میتواند به صورت موازی انجام شود. دوباره نگاهی به عملیات شکل اول بیندازیم:
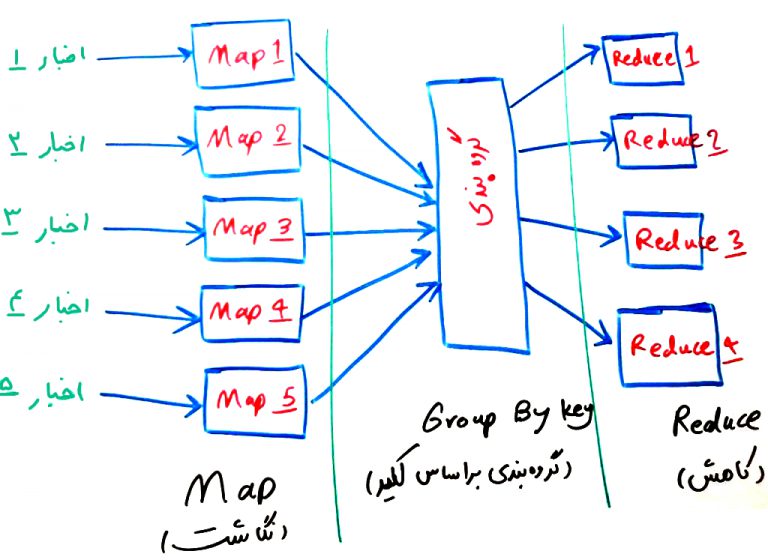
قسمتهای مختلفی در شکل بالا میتواند به صورت مستقل و موازی اجرا شود. مثلا در قسمت Map، در مثال بالا، هر کدام از ۵قسمت میتواند به صورت مستقل و موازی ترجیحا در کامپیوترهای مختلف (در یک سیستم توزیع شده) اجرا شوند. عملیات Reduce هم به همین نحوه میتواند انجام شود و هر کدام از Reducerها (کاهندهها) میتوانند در یک کامپیوتر موازی اجرا شوند. در واقع علمیات Map Reduce میتواند به صورت موازی در یک سیستم توزیع شده با تعداد بسیار زیادی کامپیوتر اجرا شود و در نهایت، خروجی مورد نظر را به یک سیستم برگرداند. در مثال بالا، ما تعداد تکرار تمامی کلمات موجود در متون را به کمک مدل Map Reduce انجام دادیم.
البته باید توجه داشت که مدل Map Reduce نیاز به یک گرداننده یا همان Coordinator دارد. در این این Coordinator است که قسمتهای مختلف را مدیریت کرده و وظایف (Tasks) مختلف را به پردازندهها یا کامپیوترهای مختلف متصل میکند. برای مثال اگر یک کامپیوتر در کل سیستم دچار مشکل شد، Coordinator میتواند وظایف مربوط به آن کامپیوتر را به کامپیوتر دیگری بسپارد و کل سیستم تا کل سیستم دچار مشکل نشود.


